Architecture🔗
The Apheris product comprises multiple components. The architecture diagram below shows the individual components and their relations on a simplified level.
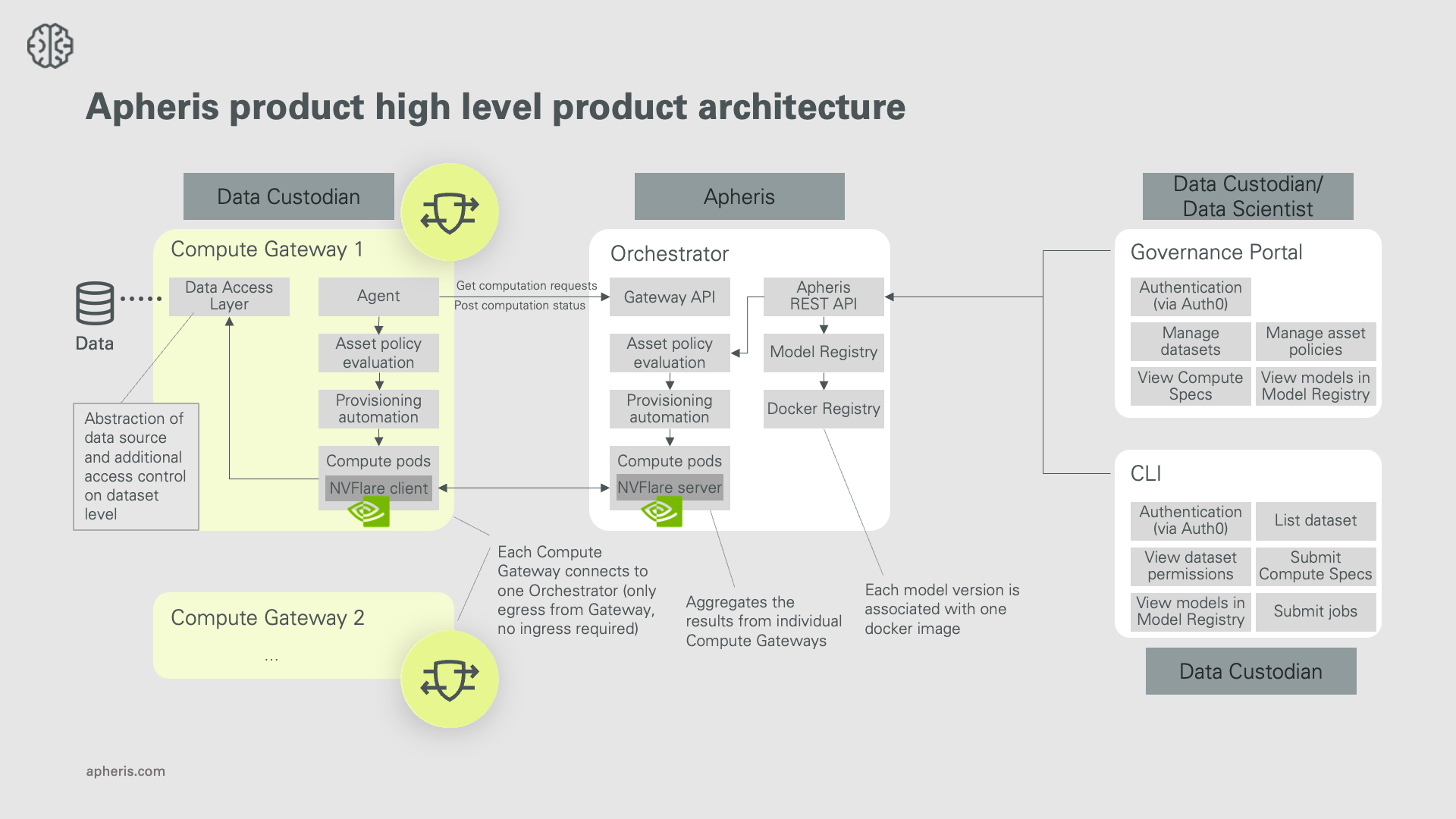
In the Apheris product, Data Scientists can run computations on the data of Data Custodian organizations, without the need to move the data itself. This is achieved through the “Apheris Compute Gateway”, a software component that a Data Custodian deploys into their environment, close to the data they want to make available for computations. The data custodian can keep their data where it currently resides and connect it to the Compute Gateway. The Compute Gateway can then execute computations on the data while enforcing access controls and PrivSec controls based on Asset Policies.
The Compute Gateway consists of an agent that regularly polls the Gateway API on the Orchestrator (egress only, no ingress), fetches new Compute Specs and the Data Access Layer service (DAL) that authorizes data access based on defined Asset Policies. This ensures that only allowed computations run on the data custodian's infrastructure.
Note
Each Compute Gateway is managed and controlled by exactly one organization in the Apheris product.
The Orchestrator is responsible for routing the Compute Specs, which are requests for computations created by Data Scientists, to the corresponding Compute Gateway, (optionally) for aggregating intermediate results coming from the Compute Gateways and for returning the results to the Data Scientist. For example, when the Data Scientist wants to run a federated machine learning computation, aggregation of the intermediate results, each coming from one Compute Gateway (e.g. using federated averaging) is then executed on the Orchestrator.
In addition, the Orchestrator also takes care of storing metadata of the datasets and the addresses of the individual datasets registered to the Compute Gateways. However, never is any real data stored in the Orchestrator.
The Apheris REST API allows for interacting with the Orchestrator. It comprises multiple sub-APIs:
- Datasets and Asset Policies API - for managing datasets, and Asset Policies, as well as receiving the permissions for a particular user on a particular dataset
- Model Registry API - for getting existing models in the Model Registry
- Compute Spec API - for managing Compute Specs and activating them
- Jobs API - for managing compute jobs on activated Compute Specs and receiving logs and results from these jobs see the CLI Jobs Reference or Python SDK
The container images for the models and components are hosted on RedHat's Quay container registry.
When using the Apheris product, you would typically use the Apheris CLI and the Governance Portal. Both of which connect to this Apheris REST API.
The Apheris CLI can be installed on your local computer and run from a terminal. The Governance Portal runs from the browser.
Logging into Apheris🔗
Before having access to the Apheris product (for both Apheris CLI and Governance Portal) you have to authenticate. Apheris uses Auth0 (by Okta) as an authentication broker. Hence to authenticate, you can either use Enterprise Single-Sign-On (SSO) using your existing identity provider or by creating and using credentials that you choose, where Auth0 plays the role of an identity provider. In any of those cases, Apheris is never an identity provider, and no user credentials are stored in the Orchestrator. Please see account setup and login for details.
Datasets, models, and asset policies🔗
Data Custodians can manage their datasets and Asset Policies through the Governance Portal, which stores this information on the Compute Orchestrator. Note that when you register a dataset, you only specify the path to the original data location but never add the real data. Hence, only the URL is stored in the Apheris Compute Orchestrator - your data always stays in your organization's environment.
Data Scientists can also use the Governance Portal to view which datasets they have access to, view the available models in the Model Registry, and then use the Apheris CLI to create Compute Specs. The Apheris CLI is distributed as a Python wheel file and can be installed on the user’s local computer. The CLI allows integration with the Apheris platform in the typical workflow of Data Scientists and ML Engineers - they can use their preferred development environment, code versioning tools, and more.
A Data Scientist's actions on the data depend on the permissions previously granted in the Asset Policies defined by the data custodian.
The Model Registry contains a list of available models with associated information like available versions of the model. Each model version is associated with exactly one model’s docker image in the docker registry.
Running computations on the Gateway🔗
Data Scientists can create, activate, check status, and shut down Compute Specs via the Apheris CLI. When the Compute Specs are created they receive a unique ID which should be passed to the CLI to manage the Compute Spec lifecycle by calling the Apheris Compute Orchestrator API as they need.
Asset Policies (which are stored on the Orchestrator) are validated at multiple steps throughout the process:
When Compute Specs are created, Asset Policy validation is performed, and if allowed the Compute Spec will be created and automatically approved.
When the Data Scientist requests an activation of a Compute Spec, the Asset Policies are validated again, and only if allowed the activation workflow will be started. This means that a Compute Pod on the Orchestrator will be created with a new NVFlare Server, and on each Gateway that is part of the Compute Spec, a Compute Pod for the NVFlare client will be created. Then the Orchestrator will make the Compute Spec available to all Gateways that are part of this Compute Spec. The Gateways will fetch the Compute Spec via the Gateway API and validate it using the Asset Policies for their datasets (the Orchestrator cannot push anything directly to the Compute Gateway, but the agent in the Compute Gateway can only fetch requests from the Orchestrator). When everything is confirmed, the NVFlare clients on the Gateways will be launched and connected to their specific NVFlare Server running on the Orchestrator.
When the Data Scientist activates a Compute Spec, the Gateway pulls the docker image associated with the model specified in the Compute Spec from the docker registry of the Model Registry. This model docker image contains all code and dependencies of the model, which cannot be altered by the Data Scientist at runtime, for security reasons. For details on how models for Apheris are created and how you can bring custom models, please refer to the guide on getting your model on Apheris.
During the activation, the Apheris product automatically provisions one compute pod on the Orchestrator (running the NVFlare server) and one on each Compute Gateway(s) (running the NVFlare client). All pods are created using the same model docker image for the model specified in the Compute Spec. The Client pods on each GW, start the communication with the Server, using the NVFlare communication based on gRPC.
For security reasons, the NVFLARE client compute pods running on the Gateways are locked down, i.e., no ingress is allowed, and egress is limited (achieved through Cilium networking policies). Additionally, any request from the NVFLARE client compute pod to the data will not go directly to the real data store but to the Data Access Layer (DAL). The DAL validates permissions of a user on the dataset level at the time data is requested and thereby enforces that the computation can only access the data it’s supposed to access based on the Asset Policy.
Once a Compute Spec is successfully activated (i.e., the containers with NVFlare client and server using the model docker images are up and running), the Data Scientist can submit jobs using the CLI. The activated Compute Spec ensures provisioned resources to run the job, while the job is the actual computation that a Data Scientist wants to run on the data. The Jobs API validates each submitted job against Asset Policies and associated model-specific PrivSec controls before the job can be executed. While the Compute Spec is activated, the Data Scientist can submit as many jobs as needed.
While a job is running, the Data Scientist can inspect its status using the Apheris CLI. When a job is finished, the Data Scientist can retrieve the results and associated logs through the Jobs API. When the Data Scientist is done with running jobs, they deactivate the Compute Spec and thus, free up the resources taken by the activated Compute Spec.
Validating Asset Policies and applying PrivSec controls🔗
As described before, for any incoming Compute Spec, the asset policies are validated at multiple points throughout the Apheris product - on the Orchestrator when a Compute Spec is created, as well as on the Compute Gateway in the agent before a computation is launched, and in the data access layer when actual data access happens. This ensures that only those computations can actually be carried out that were allowed by the data custodian in the Asset Policies.
Asset Policies can also include model-specific PrivSec controls. In the case of Apheris Statistics it includes privacy settings e.g. bounded privacy. Generally, each model is responsible for defining its own PrivSec controls, and how and where to apply them in the flow of computations. For Apheris Statistics, some controls are applied on the Gateway side as part of the pre-processing, while others are applied on the Orchestrator before the result is returned to the user.
Security by design🔗
Throughout the Apheris product, multiple security measures are implemented by design.
One key design principle is that computations on data can only be executed if Asset Policies allow for that. By default, no permissions are associated with a dataset in the Apheris platform. Hence, Data Scientists cannot analyze data unless they are granted permission in the Asset Policies by the Data Custodian controlling the data. Also within your organization, it is necessary to grant someone access to your own organization’s data, you have to specify an Asset Policy for the dataset.
Another key design principle is that there is no ingress on the Compute Gateway - only egress. This means that there is no way to directly connect to the Compute Gateway from the outside or push anything directly to it. Rather, the Compute Gateway has to poll the Orchestrator for any incoming requests. This significantly increases the security of the Compute Gateway, as no ingress needs to be enabled on the Compute Gateway and hence on the data custodian environment (i.e., the data custodian does not need to open ports in their environment).
The same logic applies to the Apheris CLI - the Compute Orchestrator can never push anything directly to the Data Scientist’s machine that runs the CLI. The Compute Orchestrator can only respond to incoming requests from both the Compute Gateway and from the Data Scientist.
Further, our Data Access Layer (DAL) on the Compute Gateway protects the data by allowing access to the datasets only to the granted users and specific models. Additionally, the Jobs API on the Orchestrator ensures that a Data Scientist cannot directly access the NVFlare Server, which increases the overall security of the system as only specific requests to the NVFlare server are allowed through the Jobs API.
All communication within the components of the Compute Gateway stays within isolated networks. All communication between a Compute Gateway and the Orchestrator is encrypted in transit (via TLS on port 443, version 1.2 or higher).
Apheris creates, manages and distributes system credentials and cryptographic keys. For system credentials, Apheris Gateways authenticate themselves against the Orchestrator using Auth0 credentials; these credentials consist of an access key ID and secret, which are generated and distributed to the customer during the onboarding process. For cryptographic keys, Apheris uses AWS KMS on the Orchestrator to generate and rotate the keys employed for encrypting various elements, such as S3 objects, EKS secrets, and EBS volumes that are used on the Orchestrator or Apheris-managed Gateways.
All dummy data files are scanned for content malware and any alerts generated are handled by the Apheris security team.
Deploying Apheris🔗
Apheris provides several options to deploy the Compute Gateway. For details on the deployment please check the Deployment guides for various setups.
The Orchestrator is in most cases deployed and operated by Apheris. In case you are interested in deploying the Orchestrator yourself, please contact your Apheris representative.