Compute Specs🔗
What is a Compute Spec🔗
A Compute Spec is a contract between a Data Scientist and a Data Custodian organization that specifies computational access to their sensitive data. A Data Scientist can submit a Compute Spec using the Apheris CLI, and a data custodian can see it in the Apheris Governance Portal.
The Compute Spec specifies the particular model and parameters for securely running statistics functions and machine learning models on specified datasets. Think of it as a blueprint that includes:
- Dataset ID: Each Compute Spec is linked to a specific dataset or datasets by an identifier. This ID is used to identify which Compute Gateways the code runs on
- Model: Each Compute Spec specifies one model in our Model Registry to run on the specified data. Generally, a model is defined through a Docker image that contains the pre-configured environment in which the code will execute. It ensures consistency and reproducibility by packaging the code, runtime, system tools, system libraries, and settings.
- Maximum Compute Resources: The Compute Spec details the required computing resources; specifically the number of virtual CPUs, the amount of RAM, and any GPU requirements, for both computations on the compute client and the compute server. Data Scientists and ML Engineers can specify the resources they want to allocate for their computations, to ensure these will meet the task's demands. The resources are allocated while a Compute Spec is activated, and they are freed up when the Compute Spec is deactivated. At the same time, Data Custodians have control over the resources they make available to the Gateway - the Data Scientists and ML Engineers can only allocate resources within these pre-determined boundaries.
In essence, a Compute Spec is a comprehensive contract between Data Scientist and Data Custodian that delineates how, where, and on what data a model code can execute within the respective Compute Gateway.
Creating Compute Specs🔗
As a Data Scientist, you create the Compute Spec using the Apheris CLI. For details on how to create Compute Specs, please refer to our tutorials for
- and our Apheris CLI specification.
When you create a Compute Spec, it is submitted from your Apheris CLI to the compute server. The data custodian organization to whom the datasets in a Compute Spec belongs, can view the incoming Compute Specs in the Apheris Governance Portal.
Important
Please note that a federated computation across multiple datasets requires that each dataset resides in a different Gateway.
Viewing and finding Compute Specs🔗
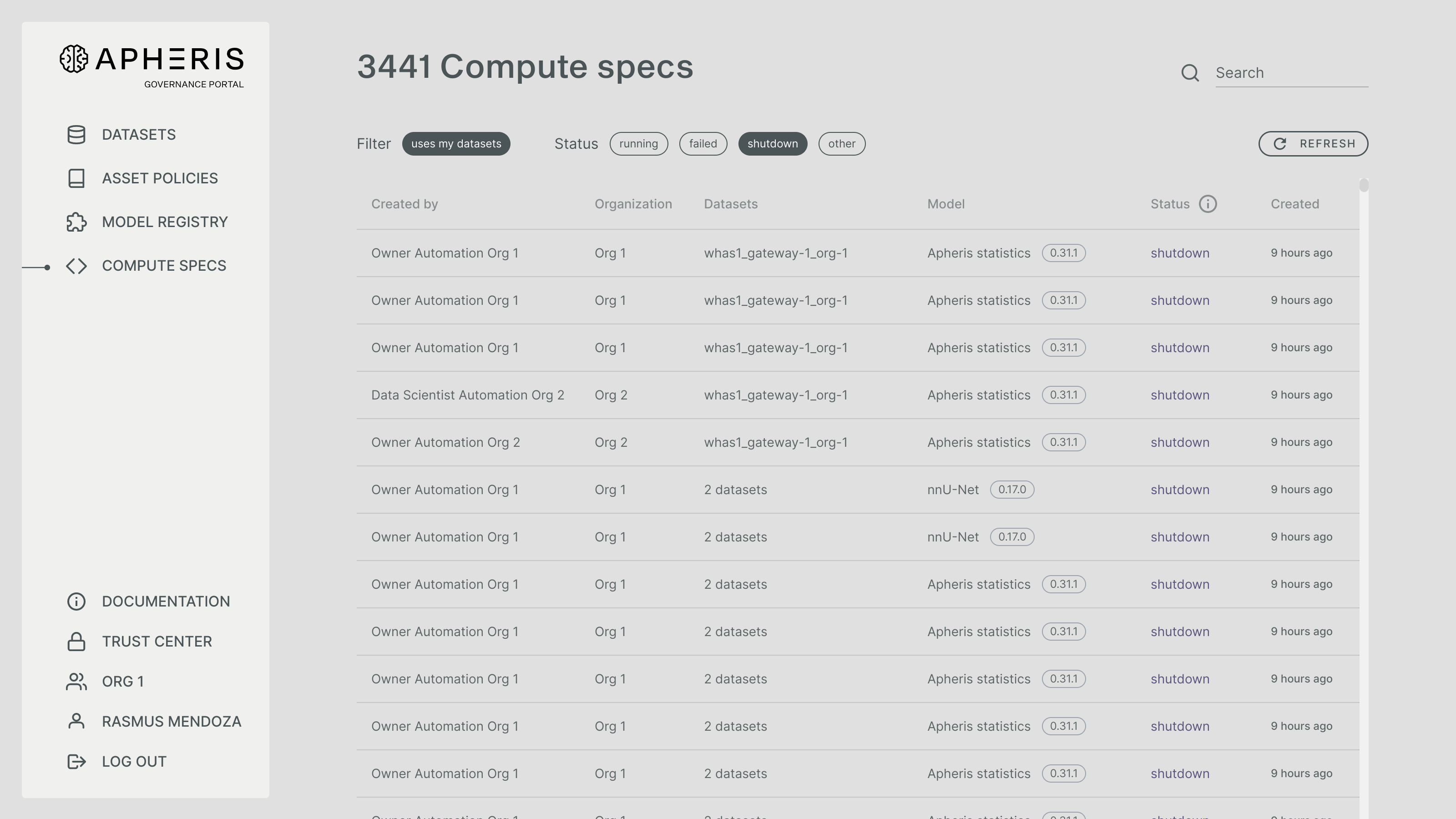
You can see an overview of all Compute Specs that use your dataset in the Apheris Governance Portal by clicking “Compute Specs” in the navigation on the left.
Here you can see a table of Compute Specs, together with the information by whom the Compute Spec was created and which organization they are from, as well as the datasets and model that they requested to use.
The Compute Spec status has a main category (that can be filtered) and a subcategory. You can learn more about the statuses in the Compute Spec life cycle documentation below.
To search for a specific Compute Spec you may use the search input in the top right corner of the page. The search input currently is restricted to the input of one identifier from the following list:
- dataset identifier
- model identifier
- Compute Spec identifier
- creators email address
Approval of Compute Specs🔗
For any Compute Spec that a Data Scientist creates, the Apheris product validates whether this Compute Spec satisfies the computational access that the corresponding data custodian has granted to this particular Data Scientist in the Asset Policy.
Imagine that you as a Data Custodian created an Asset Policy, in which you gave Data Scientist X the permission to run model Y with specific parameters on your dataset Z. Then any Compute Spec that a Data Scientist creates which doesn't satisfy this (or other) Asset Policies you have defined is rejected. And any Compute Spec that satisfies the defined Asset Policies is automatically approved. Hence there is no manual approval step for you as a Data Custodian, hence you control what computational access you want to grant to a Data Scientist via Asset Policies.
Compute Spec Life Cycle🔗
A Compute Spec can have one of the following statuses:
activerunningThe compute server and all compute clients are running.running idleThe compute server and all compute clients are running but there are no jobs active.
updatingcreatingAt least one compute client or the compute server is creating.awaiting resourcesAt least one compute client or the compute server is waiting for resources.deletingAt least one compute client or the compute server is being deleted.
inactiveawaiting activationThe Compute Spec has not been activated yet.shutdownAll compute clients and the the compute server have been shutdown.
failedfailedAt least one compute client or the compute server has failed.invalidThe state is invalid.
An approved Compute Spec allows the Data Scientist to run compute jobs on the data. To do this, first, you as a Data Scientist activate the Compute Spec that is in awaiting activation or shutdown status. This means that the resources specified in the Compute Spec as well as the model code are provisioned (both on the compute server as well as on the compute client), so that you are in a ready state to run actual computations. During activation, you might see Compute Spec status changing to creating or awaiting resources.
Concretely, when you activate a Compute Spec, this means the Apheris product will provision one NVFlare server on the compute server, and one NVFlare client on each compute client that contains datasets as specified in the Compute Spec. Generally, a compute client can have multiple activated Compute Specs in parallel (as much as the resources of the infrastructure the compute client is deployed in will allow for).
On the first activation of a Compute Spec, there will be a short delay (up to 2-3 mins on first run) while the corresponding resources are being provisioned. Once the Compute Spec is successfully activated and its status transitions to running, you can submit as many compute jobs using the Apheris CLI as you like. Each job will run immediately on the provisioned resources.
Upon completing your data science tasks, you can deactivate the Compute Spec, which will free any previously provisioned resources. While cleanup is in progress, the Compute Spec will remain in deleting status and eventually transitions into shutdown. As long as the Compute Spec is approved, you can activate and deactivate the same Compute Spec as often as you want. In order to maximize a Compute compute client's free resources we also automate the deactivation Compute Specs by using idle culling.
If any of the servers or clients fail to start, the Compute Spec will transition to failed status.
invalid status reflects that the Compute Spec is not well-formed or does not meet the necessary criteria for execution. If you see this status, you should contact your Apheris representative to troubleshoot the issue.
Note
As the creator of a Compute Spec, you can always deactivate it, even if you no longer have access granted to the datasets referenced in it.
Scalability of Compute Specs🔗
For a specific Compute Spec ID, you can have only one activation at the same time - so there can never be two activated Compute Specs in parallel for the same Compute Spec ID. If you want to scale horizontally, i.e. run computations in parallel, you need to create further Compute Specs with the same content as the first one. Each Compute Spec you create needs to be activated separately and will get its own Compute Spec ID. These can then run multiple computations in parallel as long as the Compute Gateways have enough resources available.
Within one Compute Spec, you can create as many jobs as you like. Jobs are run sequentially using a queuing mechanisms provided by NVIDIA FLARE.
In order to scale vertically, you can change the hardware requirements in the Compute Spec you create.
Culling Idle Compute Specs🔗
The Global Environment Culling feature automatically identifies and terminates idle Compute Specs across all Compute Gateways. This feature ensures optimal resource utilization by removing inactive Compute Specs, allowing the system to allocate resources more efficiently. Apheris can configure this feature upon customer request during deployment.
A Compute Spec is deemed idle and eligible for termination if it has not had any running Compute Spec Jobs within a specified duration. Such Compute Specs would be shown with running idle status in the Apheris Governance Portal.
This duration, referred to as the 'idle threshold', is configurable to suit different operational needs.
Configuration🔗
The environment culling feature can be globally configured with the following options:
environmentCulling:
enabled: true
schedule: "0 23 * * *"
timezone: "UTC"
threshold: "12h"
Enabled: Set to true to enable automatic cleanup of idle Compute Specs globally.
Schedule: Specifies when the cleanup process runs. It follows cron syntax.
Timezone: Defines the timezone in which the schedule should be interpreted.
Threshold: Determines how long a Compute Specs can remain idle before it is eligible for termination.
Please contact your Apheris representative if you want to change the default configuration for this feature in your environment.
Handling Failed Computations🔗
In addition to managing idle resources, the system ensures that failed or unrecoverable computations are addressed appropriately.
These computations may occasionally remain active, unnecessarily reserving valuable resources.
Examples include:
- Computations that fail to initialize or proceed as expected.
- Processes that become unresponsive due to unforeseen issues, such as readiness failures or resource constraints.
The culling feature ensures that such scenarios are handled effectively, minimizing the impact on system performance and resource availability.